Building a container orchestrator
Kubernetes is not exactly the most fun piece of technology around. Learning it isn’t easy, and learning the surrounding ecosystem is even harder. Even those who have managed to tame it are still afraid of getting paged by an ETCD cluster corruption, a Kubelet certificate expiration, or the DNS breaking down (and somehow, it’s always the DNS).

If you’re like me, the thought of making your own orchestrator has crossed your mind a few times. The result would, of course, be a magical piece of technology that is both simple to learn and wouldn’t break down every weekend.
Sadly, the task seems daunting. Kubernetes is a multi-million lines of code project which has been worked on for more than a decade.
The good thing is someone wrote a book that can serve as a good starting point to explore the idea of building our own container orchestrator. This book is named “Build an Orchestrator in Go”, written by Tim Boring, published by Manning.
The tasks
The basic unit of our container orchestrator is called a “task”. A task represents a single container. It contains configuration data, like the container’s name, image and exposed ports. Most importantly, it indicates the container state, and so acts as a state machine. The state of a task can be Pending, Scheduled, Running, Completed or Failed.
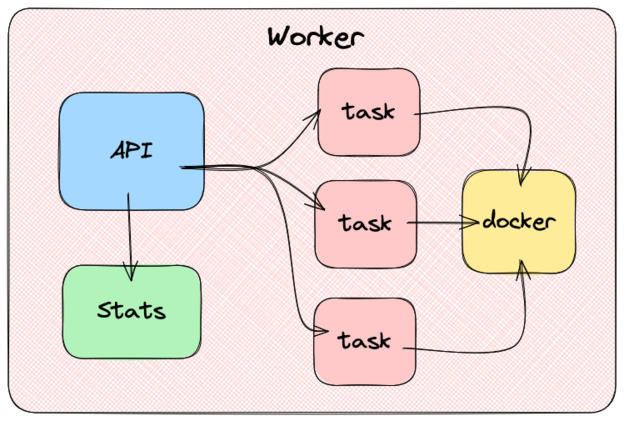
Each task will need to interact with a container runtime, through a client. In the book, we use Docker (aka Moby). The client will get its configuration from the task and then proceed to pull the image, create the container and start it. When it is time to finish the task, it will stop the container and remove it.
The workers
Above the task, we have workers. Each machine in the cluster runs a worker. Workers expose an API through which they receive commands. Those commands are added to a queue to be processed asynchronously. When the queue gets processed, the worker will start or stop tasks using the container client.
In addition to exposing the ability to start and stop tasks, the worker must be able to list all the tasks running on it. This demands keeping a task database in the worker’s memory and updating it every time a task change’s state.
The worker also needs to be able to provide information about its resources, like the available CPU and memory.
The book suggests reading the /proc Linux file system using goprocinfo, but since I use a Mac, I used gopsutil.
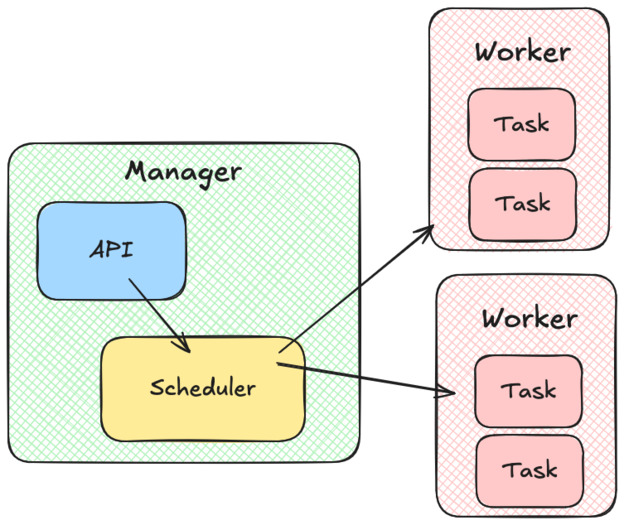
The manager
On top of our cluster of workers, we have the manager. The manager also exposes an API, which allows us to start, stop, and list tasks on the cluster.
Every time we want to create a new task, the manager will call a scheduler component. The scheduler has to list the workers that can accept more tasks, assign them a score by suitability and return the best one. When this is done, the manager will send the work to be done using the worker’s API.
In the book, the author also suggests that the manager component should keep track of every tasks state by performing regular health checks.
Health checks typically consist of querying an HTTP endpoint (i.e. /ready) and checking if it returns 200.
In case a health check fails, the manager asks the worker to restart the task.
I’m not sure if I agree with this idea. This could lead to the manager and worker having differing opinions about a task state. It will also cause scaling issues: the manager workload will have to grow linearly as we add tasks, and not just when we add workers.
As far as I know, in Kubernetes, Kubelet (the equivalent of the worker here) is responsible for performing health checks.
The CLI
The last part of the project is to create a CLI to make sure our new orchestrator can be used without having to resort to firing up curl. The CLI needs to implement the following features:
- start a worker
- start a manager
- run a task in the cluster
- stop a task
- get the task status
- get the worker node status
Using cobra makes this part fairly straightforward. It lets you create very modern feeling command-line apps, with properly formatted help commands and easy argument parsing.
Once this is done, we almost have a fully functional orchestrator. We just need to add authentication. And maybe some kind of DaemonSet implementation would be nice. And a way to handle mounting volumes…